Updates 2025/12/11
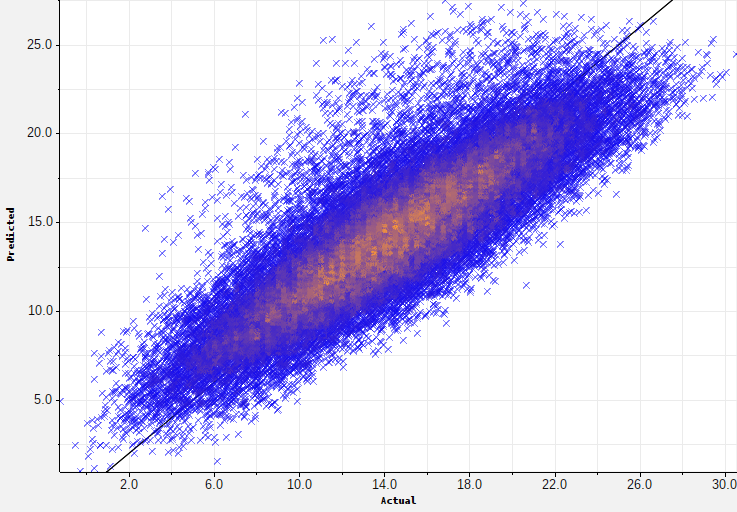
Good news: Java 25 is now supported for running ADAMS! There is also density-based scatter plots available (great for actual vs predicted regression plots), many performance improvements (mostly for spectral processing), support for a new plotting library called XChart (since the JFreeChart project has been retired), and also an experimental Step over button in the debug panel of the Flow editor (skips actor/sub-flow).
Fixes
-
adams-core:
fixed positioning of right-click menu on combobox of suggested classnames in the GenericObjectEditor.
Converting filenames to placeholder ones now favors the shortest placeholders if there is a tie between two placeholders in how much they are reducing the length of the filename.
The spreadsheet formula parser now handles the NOT/AND/OR functions.
Spreadsheets can opt to just store formulas now but never evaluated them, e.g., for preserving formulas with functions that are not supported by ADAMS (spreadsheet reader option onlyStoreFormulas); output of stacktraces from parse errors of formulas can be suppressed with the quiet option of readers.
The Show changes menu item in the Flow editor's Edit menu works again (stopped working due to changes to the underlying format used for the undos).
The Statistics menu option in the View menu of the Flow editor now allows generating statistics below a certain actor rather than just the full flow: it prompts the user if an actor other than the root one is selected. A fast statistic overview over the full flow can always be generated via the File > Properties menu option and then clicking on the Statistics button.
Tables that support column filters can apply multiple column filters now.
The Recent actor processors menu item in the Flow editor (menu Edit) is now more robust and handles non-existent actor processors now - a scenario that can occur when switching between ADAMS applications that have different modules.
Fixed performance bottlenecks of AbstractDataContainer-derived classes (addAll, getClone). Outlier detectors are now much faster when they create a copy of the container before adding their notes.
adams-compress: The NewArchive source can have a variable attached to the output option now without causing an error that the output is pointing to a directory.
-
adams-spectral-2dim-core:
Fixed performance isses of filters like DownSample, SubRange, SavitzkyGolay etc by adding data points via the new replaceAll method in ordered fashion, avoiding costly insertion/sorting.
Changes
-
adams-applications:
Debian package dependencies now support Java 25 as well.
Added adams-rats-net as dependency to adams-annotator application.
-
adams-core:
The GenericObjectEditor can load/save gzip-compressed object setups now as well, if they have the .model.gz or .ser.gz extension. .txt is now a supported extension for command-line and nested command-line formats as well.
The CirclePaintlet now can fill in the circles as well.
The Standalones standalone actor can execute its sub-actors now in paralle as well, if that should make sense.
The timed actors TimedSoure, TimedSubProcess, TimedTee and TimedTrigger will output the timing either via logger or just on stdout if there is no callable actor specified and optional is ticked.
The Sleep control actor now allows indefinite sleeping.
The EndlessLoop template now uses a Sleep actor with indefinite sleeping, to avoid interfering with debugging.
The Branch actor can now remove the upper limit for number of threads.
IncVariable and IncStorageValue can now suppress notifications being sent to change listeners, useful for variables in high-throughput scenarios that are only used as a counter.
Added support for binary files to the SplitFile transformer and the MergeFiles sink.
Changing the logging level no longer calls the reset() method, allowing on-the-fly changing of levels.
The Deserialize transformer now allows updating the logging level.
Added an experimental Step over button to the debug panel in the Flow editor, which allows skipping of actors and sub-flows for faster debugging.
adams-groovy: Upgraded Groovy to 5.0.3 to make it compatible with Java 25.
adams-net: Upgraded tika-core to 3.2.2 to address CVE-2025-66516
adams-scripts and adams-scripts-debian: All scripts now add the flag --enable-native-access=ALL-UNNAMED for Java 17 and later.
-
adams-spectral-2dim-core:
The ZippedSpectrumReader now supports companion files (.txt) that list sample IDs that are to be ignored. That way, the archives don't need to be updated but spectra can still be excluded from being loaded.
The MinMax spectrum outlier now allows turning on/off the lower/upper bounds for the checks to make it easier to just enforce one bound.
-
adams-spreadsheet:
The JFreeChartPlot and JFreeChartFileWriter sinks now have watermark support as well.
Additions
-
adams-core:
General support for watermarks within ADAMS, available as general and XYSequence paintlets, which can be used for branding. Can be specified in the Weka Investigator in the Classifier Errors as overlay paintlet.
Added ExtractGroup, ExtractID, UpdateGroup and UpdateID transformers.
Added StandaloneSubFlow standalone actor that can define its own mini-subflow, but still operates within the same variable/storage space.
Added the ReportValueMatches boolean flow condition that checks whether the specified report field has a specific value.
Added the Xor boolean condition which outputs the logical XOR (exclusive OR) of the result of the two base boolean conditions.
Added the DirChanged transformer with its class hierarchy of schemes for determining whether a directory has changed.
Added the DirChanged boolean flow condition and DirMonitor flow restart trigger that use the new directory change monitor class hierarchy.
Added a class hierarchy for updating logging levels in objects.
Added the UpdateLoggingLevel transformer for updating the logging levels of objects passing through using the new class hierarchy of updater schemes.
adams-excel: Added the FastExcelSpreadSheetReader/Writer plugins for reader and writing MS Excel xslx spreadsheets.
-
adams-spectral-2dim-core:
Added the SpectrumSupplier source that outputs spectra compared to the SpectrumIdSupplier, which only outputs DB IDs or sample IDs.
-
adams-spreadsheet:
Added the DensityScatterPlot chart generator for JFreeChart-based charts/plots, supporting binning/histogram and kernel density estimation (KDE).
Added the HasCell boolean condition that checks whether the cell at the specified location is present, non-missing and non-empty. Optionally, can check against a specific value as well.
Added support for plotting using the XChart library (https://github.com/knowm/XChart): XChartFileWriter, XChartPlot, MakeXChartDataset, StorageXChartAddDataset.
-
adams-weka and adams-weka-lts:
Added dummy classifier AttributeAsPredictionClassifier (package functions) that outputs the value of the specified attribute as prediction (workaround for making use of co-variables in Stacking).
Added UpdateStackingNumFolds actor processor.
Added MinMax evaluation metric which outputs the min/max class value for numeric class attributes in the evaluation summary output.
The EvaluationMetricManager.props config file allows enabling/disabling ADAMS-specific Weka evaluation metrics.
The MathExprClassRegressor meta-classifier allows one to specify a transform and inverse-transform expression for converting the class values for the base classifier. Default setup uses the same expressions as LogClassRegressor.