20.1.0 released
ADAMS 20.1.0 has been released. More details and download links are available from here.
ADAMS 20.1.0 has been released. More details and download links are available from here.
Last update before the Xmas break. Unfortunately, other projects got in the way and I didn't quite get around to making a release. Oh well, this will happen in the new year. :-)
Fixes
adams-imaging: The CallableActorScreenshot control actor now works properly again when just outputting a BufferedImageContainer.
adams-rats: Rat can have variables again that get set at runtime.
adams-spreadsheet: The SpreadSheetReorderColumns transformer now leaves the cell types intact.
adams-spectral-2dim-core: the exportVisibleSpectra method of the SpectrumPanel is now more robust (accessible through the Export visible spectra popup menu item).
adams-weka and adams-weka-lts:
static class listing now works with the Weka class hierarchies as well.
the Copy cell of the InstancesTable (as used in the Data tab of the Weka Investigator) now copies the correct content.
Changes
Renderers in the object tree view of the debug panel in the Flow editor now cache their view whenever possible, to keep views more consistent between tokens.
adams-spreadsheet: The renderer for spreadsheets in the Flow debugger now only displays a maximum of 100 rows by default, with a button to display the rest if there are more. This avoids very large spreadsheets to bring the system to its knees.
adams-weka and adams-weka-lts:
The renderer for Instances in the Flow debugger now only displays a maximum of 100 rows by default, with a button to display the rest if there are more. Speeds up rendering and with that debugging.
The random split action available from the data table of the Weka Investigator now remembers the last entered values and also allows the user to select the type of splitter to use.
Additions
Added a class hierarchy for text renderers for specific object types (adams.data.textrenderer.TextRenderer). These renderers can be used in the flow with the TextRenderer transformer. The tokens in the flow now uses these to render their payloads as well, to avoid very large text outputs in the flow debugger.
adams-weka and adams-weka-lts:
added the WekaSplitGenerator for applying any available split generator, not limited to splitters for random or cross-validation splits.
added the MultiLevelSplitGenerator for splitting datasets on multiple string/nominal attributes subsequently.
The main thing to be aware of is that workflows are now a lot stricter about variables: actors now check before first execution if all variables attached to them are present. The SetVariable actors and any actor updating storage items check every time when executed whether the variables attached to the variable/storage name are present.
Fixes
adams-ml:
The SimpleArffSpreadSheetWriter now handles dates correctly. Long values get treated separately from doubles as well, to avoid loss of information (e.g., when loading Tweet IDs).
The SimpleArffSpreadSheetReader now tests for long values as well when reading numeric attributes, to avoid loss of information.
adams-weka and adams-weka-lts:
The SimpleArffLoader now handles quoted attribute names correctly, unquoting them properly.
Changes
In order to avoid strange behavior due to typos in variable names, the preExecute method of an actor now checks whether all variables used by it are valid (ie present). The check only gets executed when the isExectuted() methods returns false (usually the first time the actor is being executed). Since this can affect a number of flows, you can turn on lenient checking by setting the environment variable INVALID_VARIABLES_LENIENT to true.
switched to 1.0.20 of debian-maven-plugin
switched to 0.1.2 of requests4j
The SelectArraySubset transformer now has buttons for selection all items, no items or inverting the selection.
adams-applications: Dynamic class discovery has been turned off for applications. Instead, these applications use class/package hierarchies generated at build time. You can turn on dynamic class discovery again easily by adding an empty ClassLister.class file in the classpath of the application, e.g., in the same directory that contains the bin sub-directory.
Added checks to SetVariable actors and relevant classes implementing StorageUpdater (like SetStorageValue) that ensure that a variable attached to variable/storage name option actually exists, to avoid accidentally storing values under the default name (avoids hard to track errors).
adams-weka and adams-weka-lts:
The Build model of the Classify and Cluster tab in the Weka Investigator now allows the data to be randomized beforehand.
The Train/test set, Train/test split, Train/validate/test set and Reevaluate model evaluation tasks in the Classify tab of the Weka Investigator now take advantage of models supporting batch prediction.
Added the "-id-test" option to the RemoveTestInstances Weka filter to allow differing indices between current dataset and test set (eg if the test set is just a list of IDs).
Additions
added conversions for converting primitive arrays (eg float[]) to/from byte arrays (IEEE754): ByteArrayToPrimitiveArray and PrimitiveArrayToByteArray.
Added the adams-groovy-rest module for writing REST plugins in Groovy.
The actor processor ListActorUsage lists all occurrences of the specified actor class.
Added Actor locations to the Find usage submenu in the Flow editor tree popup, listing all occurrences of the currently selected actor class.
adams-imaging:
added reader for object locations stored in spreadsheets: ObjectLocationsSpreadSheetReader
adams-ml:
added GroupedTrainTestSplit, GroupedCrossValidation, TrainValidateTestSplit and GroupedTrainValidateTestSplit dataset preparation schemes for the PrepareFileBasedDataset transformer.
adams-spreadsheet:
Added dummy AllFinder for locating all columns and rows.
adams-spectral-2dim-core:
The Oscillating outlier detector can be used to detect spectra that look like an oscillating signal.
The SpectrumToArray conversion turns either the wave numbers or the amplitudes of the spectrum into a float array.
adams-weka and adams-weka-lts:
Added the LogClassRegressor meta-classifier, which only logs the class attribute, opposed to the LogTargetRegressor which also logs any other numeric attribute.
Added dummy AllFinder for locating all columns and rows.
The WekaEnsembleGenerator allows the creation of ensembles in the flow: e.g., with the VotedModels generator, an array for Weka classifiers can be turned into a Vote meta-classifier, bypassing the training of the Vote classifier itself. The MultipleClassifiersCombinerModels generator allows you to use any classifier derived from MultipleClassifiersCombiner.
Lots of minor changes and fixes happened over the last few weeks. But the most notable one is the generation of Debian and Redhat installer packages. These make it easier to install ADAMS on servers or in Docker images. Also, with the adams-maven-plugin it is now possible to compile flows into Java code during the build process.
Fixes
The use of databases other than MySQL in case the adams-db module is present now uses auto-detection again for determining the backend (using the JDBC URL). This avoids having to explicitly configure a DbBackend.props file.
The LocalScopeTransformer and LocalScopeTrigger actors now only clean up local variables and storage data structures if not using shared resources.
The forceVariables method in the AbstractActor (ancestor for pretty much all actosr) no longer calls cleanUp of current Variables instance: this caused havoc when dynamically instantiating sub-flows at runtime, linking them into the existing flow to have access to variables and storage, as they could remove the outer flow's variables altogether.
adams-net: The Base64ToString conversion now applies the selected decoding type.
adams-imaging:
The BinaryCrop cropping algorithm now works for objects of any shape, by finding the rectangle encompassing the center object.
The NegativeRegions transformer now sets the supplied object type.
The MinDimensions negative regions meta-algorithm no longer removes two objects at a time when logging is enabled.
adams-json: retrieving an array via $.expr no longer results in the elements being forwarded one-by-one, but as a JSONArray object (JSONArray also implements the List interface, which got interpreted incorrectly; $.expr can return more than one value).
adams-addons-all: now has a dependency on adams-tensorflow as well.
Changes
Flows that had errors when loading, the string " (incomplete)" is now appended to the filename, to mark them as such. Previously, the filename got lost and a simple "FlowXYZ" was used.
The TextFileReader now accepts InputStream objects as well.
upgraded java-utils dependency to 0.0.3
upgraded commons-compress dependency to 1.19 to address CVE-2019-12402 (https://nvd.nist.gov/vuln/detail/CVE-2019-12402)
The PromptUser template now allows configuring the restoration of settings as well.
The adams.core.logging.FileHandler logging output handler now makes use of the ADAMS_LOGFILE_PREFIX environment variable to inject a prefix into the log file (eg, "console.log" becomes "testing-console.log" with "ADAMS_LOGFILE_PREFIX=testing-"). This allows multiple log outputs from multiple ADAMS services on the same server.
The Preview browser now offers a search panel when viewing spreadsheets and no longer outputs exceptions in the console in case custom preview handlers cannot be instantiated (eg when switching from one ADAMS application to another).
The ImageAnnotator transformer now maintains last selected label, window position and size between invocations.
adams-json:
upgraded jsonpath dependency to 2.4.0
The StringToJson conversion how has an output type option for casting the JSON object (any, array, object).
adams-ml: The ActualVsPredictedPlot now exposes the overlays for the plot, allowing to add other ones in addition to the diagonal (StraightLineOverlay), like LinearRegressionOverlay.
adams-weka: upgraded multisearch-weka-package dependency to 2019.10.4
adams-weka and adams-weka-lts: The ActualVsPredictedPlot now exposes the overlays for the plot, allowing to add other ones in addition to the diagonal (StraightLineOverlay), like LinearRegressionOverlay.
adams-meta: The FlowFileReader now accepts InputStream and Reader objects as well (must be closed separately).
as it occurs rather than all of it after the rsync process finishes.
adams-spreadsheet: The SpreadSheetFileReader now accepts InputStream and Reader objects as well (must be closed separately).
All ADAMS applications are now available as Debian and RPM packages as well.
Additions
Added support for InputStream/Reader instance generation via the InputStreamGenerator/ReaderGenerator sources and the CloseInputStream/CloseReader sink. This allows loading files from the classpath, e.g., files that are packaged within the jars of an application.
Added BooleanToString and StringToBoolean conversions.
With the ForwardSlashSwitch actor processor, it is now possible to switch all ForwardSlashSupporter objects in one go.
adams-rest:
added RESTPlugin support for processing text and JSON with a callable transformer template ("pipeline"): CallableJsonPipeline, CallableTextPipeline.
added RESTplugin for just calling callable transformer with JSON or text: CallableJsonTransformer and CallableTextTransformer.
adams-maven-plugin: a Maven plugin that allows compilation of flows into Java code as part of the Maven build process.
adams-spectral-2dim-core: added the Export spectra... plugin to the SpreadSheet and Instances tables to allow export of selected rows as spectral files.
adams-weka and adams-weka-lts:
added the conversion MapToWekaInstance and WekaInstanceToMap to provide an easy way to convert Weka Instance objects to JSON and vice versa.
introduced a class hierarchy for building a final model after a cross-validation run of a classifier in the Weka Investigator.
added filter for extracting a range of instances from a dataset in the specified order: KeepRange.
Didn't get around to posting it last Friday, as I ran out of time.
Notably are the refactoring underneath the hood, slimming down the adams-core module by moving out support for additional databases to adams-db, math-stuff to adams-math, XML processing to adams-xml, YAML support to adams-yaml and JSON handling to adams-json. Furthermore, the adams-rats module is now a meta-module, with the actual functionality split into adams-rats-core , adams-rats-net, adams-rats-rest and adams-rats-webservice. This allows for slimmer applications, e.g., when a simple REST service is required, there is no need to pull in SOAP related dependencies. These changes were triggered by generating a smaller standalone application for the data exchange server, which is to be used in conjunction with RabbitMQ (DEX is used for storing the actual payloads of the RabbitMQ messages).
Most HTTP-related queries are now handled using the requests4j library (https://github.com/fracpete/requests4j).
Fixes
The customColumnHeaders option of the CsvSpreadSheetReader now works also without having to check the noHeader option.
adams-net: HttpPostFile now uses correct CRLF in POST rather than just LF, according to specifications.
adams-weka and adams-weka-lts:
When the WekaFilter transformer initializes the actual filter, the error message no longer gets discarded; it is also possible to update properties with variables that access an array of the underlying filter.
The Associate, Attribute selection, Classify and Cluster tab in the Weka Investigator can once again get copied (deserialization of output generators was failing).
The SimpleArffLoader now supports attribute weights, fixed instance weights handling.
Changes
In the Debug control panel, it is now possible to hide programmatic variables in the Variables tab, by checking the Show user-only vars checkbox.
The AddActorHere/After/Beneath keyboard actions of the Flow editor now allow you to specify whether you want to edit this actor in a GOE window and if that is the case whether you want to see the class tree of actors.
Added methods contains(str, find) and replaceall(str, find, replace) to the BooleanExpression, MathematicalExpression and StringExpression parsers.
Report fields now allow inline editing in the GenericObjectEditor.
Large tables now render faster in general, by not enforcing to calulate the optimal width anymore.
Errors/warnings encountered during loading a flow are now displayed in the notification area rather than in separate dialogs.
Moved markdown support from adams-core to adams-html.
Removed JShell support (not really practical).
Moved terminal-based application support (using lanterna) into adams-terminal module.
Moved math-related libraries and functions into adams-math module.
Moved XML, XSLT, XPath related actors and code into adams-xml module.
Moved YAML related actors and code into adams-yaml module.
adams-rats: split into adams-rats-core, adams-rats-net, adams-rats-rest and adams-rats-webservice to be able to build more lightweight applications.
adams-rsync: upgraded rsync4j to 3.1.2-16
adams-html:
added requests4j library as dependency
removed JSoup dependecy
adams-net:
upgraded tika-core to 1.22 to address https://nvd.nist.gov/vuln/detail/CVE-2019-10094 and https://nvd.nist.gov/vuln/detail/CVE-2019-10088
upgraded jsch to 0.1.55
added requests4j library as dependency
removed JSoup dependecy
adams-spectral-2dim-core:
The Spectrum Explorer now allows the user to create a new window or to duplicate the current one. It now also allows to stop the execution of the current action via Scripts - Stop execution.
The SpectrumPaintlet now has the option paintAll to force drawing all points.
adams-spreadsheet:
the header and cell popup menu items for the spreadsheet table have been reworked to work more consistently across visible/selected rows.
The SpreadSheetColumnIterator can now output 1-based indices instead of names and also output the items as an array rather than one-by-one.
adams-weka and adams-weka-lts:
the header and cell popup menu items for the instances table have been reworked to work more consistently across visible/selected rows.
WekaInstancesInfo now allows outputting the name of the class attribute via CLASS_ATTRIBUTE_NAME
Blacklisted the ArffViewer and SqlViewer menu items.
Added support for per-fold output in Classify tab of the Weka Investigator
The Weka Investigator now allows changing attribute and instance weights.
upgraded version of datasets-weights-weka-package to 2019.9.13
removed cat swarm optimization support (CSO), since not working properly
Additions
The Flow editor received new keyboard actions: ActionQuickSearch (search for available menu items or tree popup actions for current context, invoked by Ctrl+Space), QuickSearchActorHere/After/Beneath (similar to SearchActorHere/After/Beneath, but uses list rather than tree).
Added a simpler, faster CSV spreadsheet reader which only supports text and doubles called FastCsvSpreadSheetReader, which is aimed at reading very large CSV files quickly.
Created the adams.core.TimeIt class for timing code executions. Its static methods generate timings for Runnable instances.
The InformationDialog sink allows displaying a simple message to the user.
With the adams.core.option.ApplyActorProducer, it is possible to generate Java code from actors that can be incorporated as methods in other projects.
Allowing export of sub-flows with the Export... menu item available from flow tree popup menu (eg generating Java code using the ApplyActorProducer).
adams-meta: the SpecifiedActor source outputs the actor identified by actor path in flow, useful when storing an actor setup in a file for reference (variables can be expanded).
adams-net:
added FTPDelete and SFTPDelete transformers
added conversions for base64 operations: Base64ToByteArray, Base64ToString, ByteArrayToBase64, StringToBase64.
adams-rabbitmq:
added support for a simple REST webservice that allows data exchange via tokens: adams.flow.rest.dex.DataExchange and adams.flow.rest.dex.DataExchangeServer.
added standalone for defining a data exchange server connection context: DataExchangeServerConnection.
added transformers for performing upload/download/remove operations on a data exchange server: DataExchangeServerDownload, DataExchangeServerRemove, DataExchangeServerUpload.
added (send/receive) converter for sending payloads via a data exchange server (which can take advantage of a DataExchangeServerConnection available through the flow context): DataExchangeServerBasedConverter.
adams-rest: added conversion JsonToObject and ObjectToJson for easy conversions of Java objects from/to JSON using Jackson's data-binding functionality (https://github.com/FasterXML/jackson-databind).
adams-spectral-2dim-core:
The ExtractIdAndTypeSpectrumReader spectrum reader allows you to post-process the sample ID and type using the specified ID and group extractors (eg using the filename from the report).
The Median multi-spectrum filter computes the median from the spectral points.
adams-spectral-3way-core: The ExtractIdAndTypeThreeWayDataReader 3-way data reader allows you to post-process the sample ID and type using the specified ID and group extractors.
adams-spreadsheet:
The content of individual spreadsheet cells can now be displayed via the View cell menu item or with the new Cell content viewer tab.
With the new Column stats tab it is possible to calculate some statistics on the fly from the currently selected column and rows (default is sum).
adams-weka and adams-weka-lts:
the content of individual instances cells can now be displayed via the View cell menu item.
added dependency for the data-dumper-weka-package
For once, there were mainly changes and additions and no fixes. In terms of changes, these were mainly to improve usability, but MOA has finally been updated to the latest release. As for additions, the ability to generate word clouds is noteworthy.
Changes
The help dialog in the GenericObjectEditor now shows the help for the current object configuration, rather than from the object with default options.
The SimplePlot and SequencePlotter sinks accept arrays of SequencePlotContainer objects now as well (for more efficient plotting).
The Flow editor now allows the following operations on all selected flows to be executed at once: validate/run/stop/clear graphical output. When applying actor processors to a flow that generate graphical output (eg finding actors, listing variable occurrences), then these no longer show up in a separate dialog but as a tab on the right hand side.
The ExecuteJobs transformer has now the ability to override the number of threads used by the incoming JobRunner instance (but only if that one implements ThreadLimiter, of course).
The SpreadSheetTable (eg used by the Spreadsheet file viewer) now allows the plotting of multiple rows.
Added the envVarOptional flag to the SetVariable standalone: if false it will generate an error if the env var is not present. An empty env var will now generate an error if overrideWithEnvVar is set to true.
Reworked the database connection dialog (from the main menu) to allow connecting to multiple databases without having to disconnect active one first. Also added buttons for creating a new connection and removing an existing one.
Plots (like Weka's error plots, sequence plots, etc) now allow the user to copy/paste the ranges between windows to align them easily.
adams-moa: MOA was upgraded to 2019.05.0 (thanks to Corey)
adams-compress: The following transformer can handle byte arrays now as well: Bzip2/UnBzip2, GZIP/GUNZIP, Lzf/UnLzf, Lzma/UnLzma, Xz/UnXz, Zstd/UnZstd.
adams-rabbitmq: BasicAuthConnectionFactory and GuestConnectionFactory now have an option for specifying the virtualhost on the RabbitMQ server.
adams-spectral-2dim-core: upgraded jcamp-dx dependency to 0.9.6.
adams-spreadsheet:
The SpreadSheetPlotGenerator transformer can output arrays of plot containers now as well (for more efficient plotting).
The row statistics now offer an option to specify the range of columns to operate on.
The popup plugins for table rows now allow the user to specify the subset of columns to operate on (eg including only subset of columns in SimplePlot/JFreeChart/Histogram).
adams-weka and adams-weka-lts:
if the WekaFileWriter sink is configured to use the relation name as file name and the provided filename points to dir, then relation name is simply appended to that directory.
The InstancesTable (eg used by the Weka Investigator) now allows plotting of multiple rows.
The popup plugins for table rows now allow the user to specify the subset of attributes to operate on (eg including only subset of columns in SimplePlot/JFreeChart/Histogram).
Additions
The ArrayNormalizeRange array statistic scales the values to the specified lower/upper bound.
The ArrayStandardize array statistic transforms the values to have a mean of 0 and a stddev of 1.
The conversion StringToByteArray turns as string into a byte array using the specified encoding and the ByteArrayToString turns it back into a string, also using the specified encoding.
adams-applications: added the .-exec* script to the Debian packages, which allows the execution of any class or flow from the command-line.
adams-ml: added a handler in the Preview browser that can generate actual vs predicted plots from CSV files.
adams-net: The HttpPostFile transformer allows you to upload a file to a specified URL using HTTP POST as "multipart/form-data".
adams-nlp: added basic support for generating word clouds using the kumo library https://github.com/kennycason/kumo.
adams-spreadsheet:
added the SpreadSheetSupporterToSpreadSheet conversion which turns any object implementing SpreadSheetSupporter into a spreadsheet.
The ArrayStatistic plugin for the InstancesTable allows you to compute statistics for the selected rows.
adams-spectral-2dim-core: added optional cross-hair tracker, can be enabled/disabled through the plot's popup menu.
adams-spectral-3way-core: added rudimentary FitsLibsReader for reading LIBS (https://en.wikipedia.org/wiki/Laser-induced_breakdown_spectroscopy) spectra in FITS format (https://fits.gsfc.nasa.gov/).
adams-weka and adams-weka-lts:
The split generators BinnedNumericClassRandomSplitGenerator and BinnedNumericClassCrossValidationFoldGenerator take the class distribution into account by using a binning algorithm to generate similar distributed train/test splits. Grouped versions are available as well.
Added the ResidualsVsPredictor and ResidualsVsFitted output generators for classification to the Weka Investigator.
The ArrayStatistic plugin for the InstancesTable allows you to compute statistics for the selected rows.
Today marks 10 years since the first code was committed to the ADAMS repository (back then still stored in an in-house subversion repository)!
Back then, ADAMS wasn't yet a standalone project, but merely the common code base between a project for processing GC-MS data and one for processing NIR data. The GC-MS research project never really took off, but the NIR one (whic started off as an unofficial side-project) was successfully turned into a commercial application. The code-based for this offshoot project was migrated to ADAMS data structures again over the last few years and a new version for processing NIR data has been successfully launched this year at Eurofins Agro in the Netherlands and Ravensdown/ARL here in New Zealand.
Recently, we embarked on better integrating deeplearning frameworks, such as Keras. These frameworks can (in theory) now be used as a regular Weka classifier thanks to the Pyro4 library which we use for exchanging data. You only need to implement the Python side of things for parsing the data and making use of it (predictions and/or training). This opens up doors for models that work better on certain domains, like data fusion, and still being able to integrate them with all the functionality within ADAMS.
Exciting times ahead!
The Flow editor, the heart of ADAMS, goes back further than the initial commit, has seen a constant evolution of features and appearance. But one thing that has never changed: never uses explicit connections between operators (or actors in ADAMS terms). It is more of a graphic programming language than other workflow engines, with flow control, variables and internal data storage. You could say that it is Scratch for Data Scientists. It leaves out the nitty-gritty details of the underlying APIs involved and allows you to concentrate on rapidly developing machine learning and data processing applications, which you can then deploy as Linux daemons or Windows services.
This version only allowed a single flow to be edited and only offered the list of actors as side panel.

Much has happened since then, multiple open flows, various context-sensitive tabs, locating of variables and storage items, much improved context-sensitive menus and object editor.

Over the years, ADAMS has added its own set of tools to better support the users in their tasks. Below are some of them:
The Weka Investigator is a much more powerful tool than the vanilla Weka Explorer. It allows you to manage multiple sessions in one interface and each session can manage multiple files and multiple tabs for the same operation (e.g., classification). It allows you to predefine various outputs for evaluations (rather than manually requesting them via popup menus) and you can also compare them side by side.
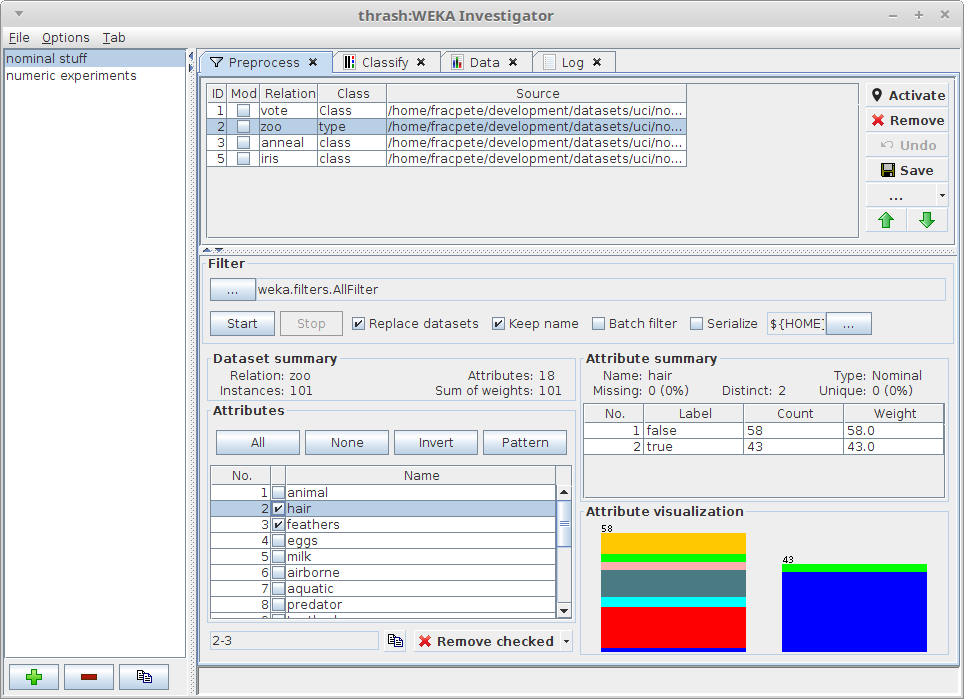
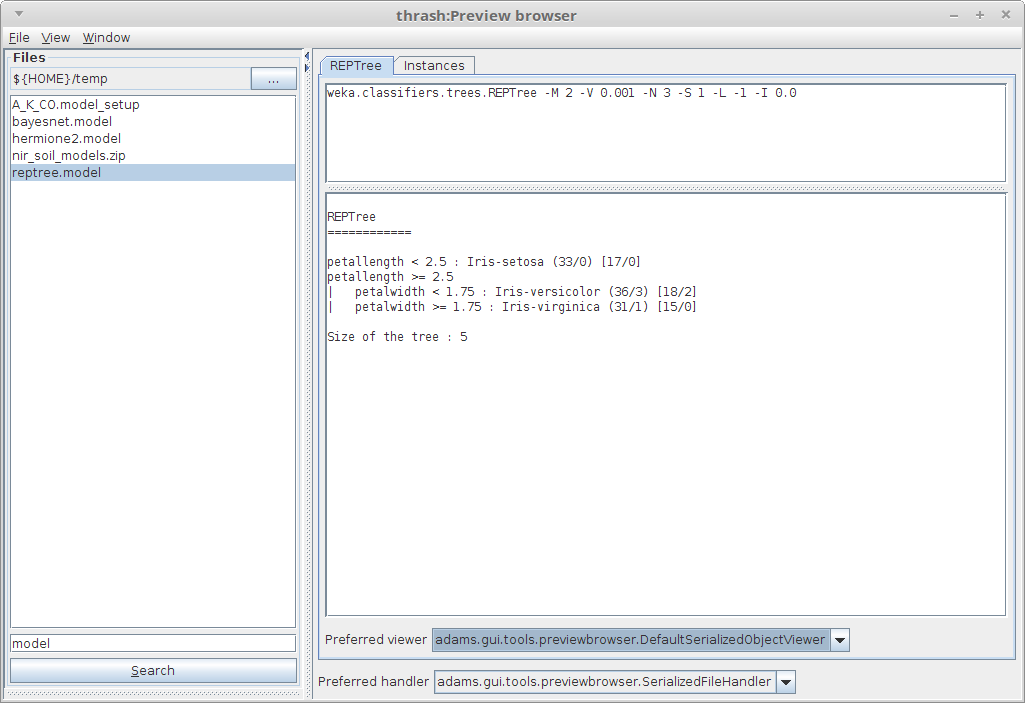
The Preview browser allows you to browse a directory and quickly display file content with various handlers. Inspect Weka models? Check! Display annotations for images? Check! Many more file types are supported.
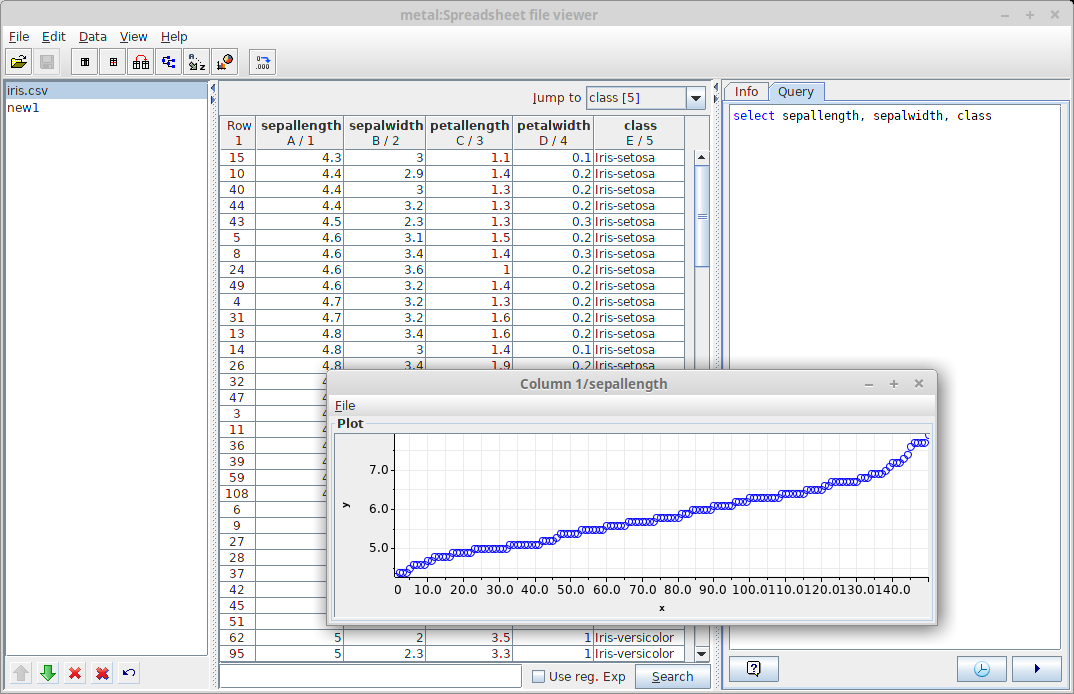
A built-in spreadsheet application that can handle many different types of file formats (depending on modules): CSV, fixed tabular, Gnumeric, ODF, MS Excel, ...
You are performing the same operation on several spreadsheets all the time? You might want to check out the Spreadsheet processor, which allows you to extract, transform and load spreadsheets of various types.

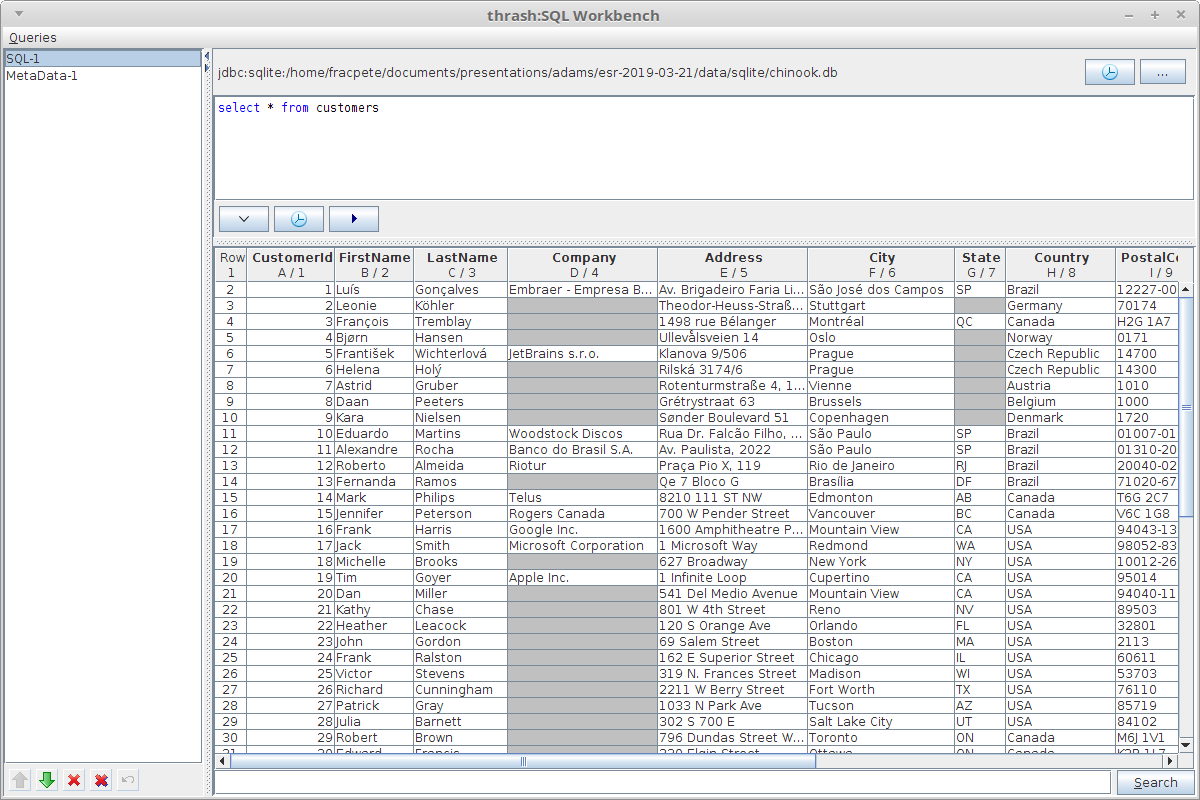
Need to work with databases then you can use the SQL Workbench to connect to (theoretically) any database via JDBC and retrieve data from it.
Need a file manager that can handle 10s of thousands of files and doesn't need minutes to display them (like the Windows File Explorer) but mere seconds? Need to copy things from/to remote servers? Then the File commander tool might be for you. It sports a two-panel layout with optional filtering, that was inspired by similar tools (Norton Commander, Midnight Commander, Double Commander).
For exploring spectral like NIR (near infrared), MIR (mid infrared), XRF (x-ray fluorescence), you can use the Spectrum explorer. It allows you to explore and filter the data and also apply PLS or PCA.
For multi-dimensional spectra, like 3D fluorescence spectra, you can use the 3-way heatmap viewer.
It is not about quantity in this update, but more about the importance of the changes.
After several weeks of incremental development and testing, I have pushed out changes regarding random split and cross-validation fold generation. To avoid duplication of code, I implemented a general framework for such operations, which is now utilized across the board (which also fixes some bugs).
Fixes
The transformers BaseName and DirName now handle placeholder abbreviations ("${...}") correctly.
adams-weka and adams-weka-lts: by moving to the generalized framework for random split and cross-validation fold generation, a number of bugs in aligning additional attributes to predictions have been fixed.
Changes
upgraded jshell-scripting to 0.1.0.
upgraded pdfbox to 2.0.16 to address https://nvd.nist.gov/vuln/detail/CVE-2019-0228
adams-ml: the file-based dataset preparation schemes for train test split and cross-validation now make use of the new generalized framework for such operations.
adams-weka and adams-weka-lts: the random split and cross-validation fold generators (both default and grouped) now make use of the new generalized framework for such operations.
Additions
adams-ml: added a generalized framework for random split and cross-validation fold generation, to be utilized in other data domains. Makes use of the work implemented for binning algorithms.
Been spending a lot of time lately on sorting out Debian package generation for Maven projects. The .deb packages available for download now make it easier to install ADAMS on Debian systems (and derivatives like Ubuntu). This includes installing them inside Docker containers. The MySQL JDBC driver is back to the old version due to a problem introduce with 6.x (my bug report is linked below).
Fixes
adams-weka and adams-weka-lts: The number of threads defined in the JobRunner used for cross-validation in the Classify tab of the Weka Investigator is no longer getting ignored.
adams-rats: fixed a race condition in the FileLister rat input scheme when used inside a Cron one, which occurred when the Cron was triggering faster than the file listing was moving the files, resulting in multiple outputs.
Changes
reverted MySQL driver back to 5.1.42, due to driver listing columns from table from any database that the database user has access to - file a bug report with MySQL regarding this https://bugs.mysql.com/bug.php?id=95717
upgraded processoutput4j to 0.0.10
upgraded jclasslocator to 0.0.14
obsolete provenance support has been completely removed.
The new ListSelectionValueDefinition class, to be used with the EnterManyValues source, is targed at pre-defined lists with a pre-selected default value (rather than just using the first list item as the DefaultValueDefinition only offers).
The SequentialDirectory, as used by the Sequence control actor (and therefore by a lot of other actors internally) has seen speed improvements for large sequences that contain multiple disabled/skipped actors. Code for storing output from last active actor in such a sequence has been optimized as well. In some cases, this reduced the actor execution overheads by 20 percent. NB: these overheads may be trivial to the other operations executed in the sequence itself. In order for this to work properly, variable support has been disabled for the skip option of actors.
introduced lenient flag in AbstractDataContainerDbReader which only outputs warnings instead of generating errors when containers cannot be loaded from DB.
Class names (ADAMS and JDK ones) are now better hyperlinked in the GUI help frame.
adams-video: updated vljc dependency to 3.12.1 (VLC player works again on Linux Mint 19.1).
Additions
The ArrayBinning statistic applies selected binning algorithm/postprocessing.
added module adams-scripts-debian for generic scripts to be used in debian packages
adams-applications: after forking the abandoned debian-maven project (http://debian-maven.sf.net/ to https://github.com/fracpete/debian-maven-plugin) and reworking the code base extensively, support for generating .deb install packages for Debian was added. and Ubuntu, using deb:package maven target.
adams-meta: The CurrentFlow source outputs the flow itself, with optional expansion of variables using their current state. Useful when trying to store the state of a flow at a certain time or when auto-generating flows.
adams-spreadsheet:
With the MakeJFreeChartDataset transformer, you can generate datasets for JFreeChart plots or file writers.
The StorageJFreeChartDataset transformer allows you to add data series to an existing JFreeChart dataset in storage, e.g., when combining plots from multiple spreadsheets.
A big push towards support for distributing jobs from anywhere within ADAMS that make use of the JobRunner interface has been happened in the last few weeks. Thanks to the new module offering RabbitMQ functionality (adams-rabbitmq, https://www.rabbitmq.com/), it is now possible to send jobs to a job queue on a RabbitMQ server and slave machines running flows for processing jobs can poll this job queue. Since the RabbitMQ server does not need to know about any slaves, it makes it easy for scaling up, by simply adding more slaves that pull jobs off the queue. Encrypting the communication via SSL/TLS is posible as well.
Furthermore, (experimental) SSL/TLS support is now available in the adams-rest module thanks to the new adams-security module.
And finally, it is now possible to monitor the memory consumption from within a flow and send out notifications (eg emails) in case the available free memory gets low over prolonged periods of time (MemoryMonitor standalone). This is something that background flows should make use of.
Fixes
Pasting a flow from the clipboard as new flow now works again. Now handles plain text nested format, command-line and nodes format.
Graphical flow components (like interactive actors such as SelectArraySubset) now work again when execute via the active flow functionality, but not being visible.
The JVisualVM menu item under Help (displayed in Developer user mode or higher) now checks whether the JVisualVM binary is actually present (no longer bundled with JDK after Java 8).
adams-weka and adams-weka-lts: ClassificationViaRegressionD classifuer now sets the class value to missing at prediction time before pushing through the filter, as MakeIndicator is taking the class value into account generating an exception if the value is invalid.
Changes
Upgraded jclasslocator dependency to 0.0.13
Upgraded java-utils dependency to 0.0.2
Upgraded MySQL JDBC driver to 8.0.16
Positions and sizes of the main tool frames are now recorded and restored.
The FindInFiles tool can search compressed files now as well (as long as the module adams-compress is present).
The SetMapValue now offers a built-in conversion for converting the value into the appropriate type, if necessary (eg string into integer).
The MemoryUsage source now also outputs init and max for heap and non-heap.
JMap and JDeps now support inline variables in the additional options parameter.
adams-rest:
experimental SSL/TLS support (only tested on self-signed certificates so far).
expanded all the missing sections in the manual.
adams-weka and adams-weka-lts:
The Weka Investigator now allows the definition of a JobRunner instead of #threads to allow for remote execution, eg via RabbitMQ. #threads can be configured within the LocalJobRunner (the default setting).
Additions
Javadoc for all classes is now available at: Javadoc
The FindInFile transformer allows to search for a text string in files, using the same functionality as the FindInFiles tool.
The ColorPerRegExpGroup meta-data color scheme, allows coloring based on a group string extracted from a label using a regular expression (eg parts of a sample ID).
Added enclose/pull up menu items in the GenericObjectEditor's popup menu for boolean conditions, conversions, spreadsheet row/column finders.
Added simple class hierarchy for sending notifications via SendNotification sink.
The MemoryMonitor standalone sends out a notification if the heap usage exceeds the specified threshold, making use of the new notification scheme class hierarchy.
Added support for generating heapdumps from within ADAMS, via main menu or through the HeapDump control actor.
The CollectionSubset transformer allows you to generate a subset collection, with only the elements from the specified indices.
Added a multi-page action to the Flow editor for comparing two flows with each other.
adams-meta: added actor for executing the actor passing through: ExecuteActor.
adams-security: new module for providing security related support, like SSL context.
adams-rabbitmq: new module for making use of the RabbitMQ message broker (https://www.rabbitmq.com/). Also includes a job runner for distributing jobs and actors for executing sub-flows remotely.
adams-rabbitmq-rats: new module for adding RabbitMQ consume/publish functionality to the RATS framework.
adams-weka and adams-weka-lts: Added enclose/pull up menu items in the GenericObjectEditor's popup menu for row/column finders working on Instances.
adams-spreadsheet: The Spreadsheet processor now has a Passthrough processor, if nothing needs to be done to the data and a Database target for storing the processed data back in a database table.